
A menudo escribimos sobre nuevos códecs de video como AV1 o H.266 y, recientemente, cubrimos formato de imagen AVIF que ofrece una relación calidad/compresión mejorada frente a WebP y JPEG, pero también se ha realizado trabajo en códecs de audio .
En particular, notamos Opus 1.2 ofrecía una calidad de voz decente con una tasa de bits tan baja como 12 kbps cuando se publicó en 2017, el lanzamiento de Opus 1.3 en 2019 mejoró aún más el códec con voz de alta calidad posible a solo 9 kbps. Pero Google AI presentó recientemente Lyra códec de tasa de bits muy baja para compresión de voz que logra una alta calidad de voz con una tasa de bits tan baja como 3 kbps.
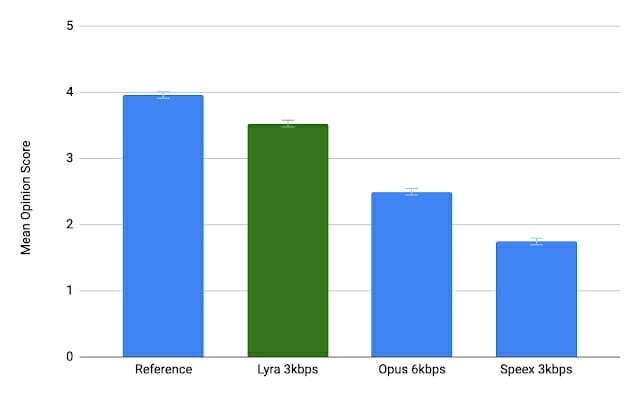
Antes de entrar en los detalles del códec Lyra, Google comparó un archivo de audio de referencia codificado con Lyra a 3 kbps, Opus a 6 kbps (la tasa de bits mínima para Opus) y Speex a 3 kbps, y los usuarios informaron que Lyra sonaba mejor. y cerca del original. De hecho, puedes probarlo tú mismo.
| Discurso limpio |
| Original |
| Opus a 6 kbps |
| Lyra a 3 kbps |
| Speex a 3 kbps |
| Entorno ruidoso |
| Original |
| Opus a 6 kbps |
| Lyra a 3 kbps |
| Speex a 3 kbps |
Speex 3kbps sonaba bastante mal para todas las muestras. Siento que Opus 6kbps y Lyra 3kbps suenan casi igual con las muestras de voz limpias, pero Lyra reproduce mejor la música de fondo en un entorno ruidoso.
Entonces, ¿cómo funciona Lyra? Google AI explica que la arquitectura básica del códec Lyra se basa en funciones (espectrogramas log mel), o atributos distintivos del habla, que representan la energía del habla en diferentes bandas de frecuencia, extraídos del habla cada 40 ms y luego comprimidos para su transmisión. En el extremo receptor, un modelo generativo utiliza esas características para recrear la señal de voz.
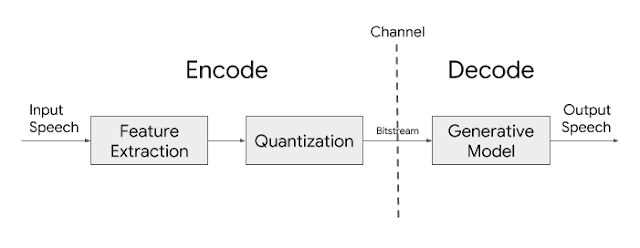
Lyra también aprovecha los modelos generativos que suenan naturales para mantener un bajo bitrate mientras se logra una alta calidad, similar a la que se logra con los códecs de bitrate más altos.
Utilizando estos modelos como base, hemos desarrollado un nuevo modelo capaz de reconstruir el habla utilizando cantidades mínimas de datos. Lyra aprovecha el poder de estos nuevos modelos generativos de sonido natural para mantener la baja tasa de bits de los códecs paramétricos mientras logra una alta calidad, a la par con los códecs de forma de onda de última generación que se utilizan en la mayoría de las plataformas de transmisión y comunicación en la actualidad. El inconveniente de los códecs de forma de onda es que logran esta alta calidad al comprimir y enviar la señal muestra por muestra, lo que requiere una tasa de bits más alta y, en la mayoría de los casos, no es necesario para lograr un habla con un sonido natural.
Una preocupación con los modelos generativos es su complejidad computacional. Lyra evita este problema mediante el uso de un modelo generativo recurrente más económico, una variación WaveRNN, que funciona a una velocidad menor, pero genera en paralelo múltiples señales en diferentes rangos de frecuencia que luego combina en una sola señal de salida a la frecuencia de muestreo deseada. Este truco permite que Lyra no solo se ejecute en servidores en la nube, sino también en el dispositivo en teléfonos de gama media en tiempo real (con una latencia de procesamiento de 90 ms, que está en línea con otros códecs de voz tradicionales). Este modelo generativo luego se entrena en miles de horas de datos de voz y se optimiza, de manera similar a WaveNet, para recrear con precisión el audio de entrada.
Lyra permitirá llamadas de voz inteligibles y de alta calidad incluso con señales de baja calidad, bajo ancho de banda y/o conexiones de red congestionadas. No solo funciona para inglés, ya que Google ha entrenado al modelo con miles de horas de audio con hablantes en más de 70 idiomas utilizando bibliotecas de audio de código abierto y luego verificando la calidad del audio con oyentes expertos y colaborativos.
La compañía también espera que las videollamadas sean posibles en una conexión de módem de marcación de 56 kbps gracias a la combinación del códec de video AV1 con el códec de audio Lyra. Una de las primeras aplicaciones en utilizar el códec de audio Lyra será la aplicación de videollamadas Google Duo , donde se utilizará en muy conexiones de ancho de banda bajo. La compañía también planea trabajar en la aceleración utilizando GPU y aceleradores de inteligencia artificial y ha comenzado a investigar si las tecnologías utilizadas para Lyra también se pueden aprovechar para crear un códec de audio de uso general para música y audio que no sea de voz. Se pueden encontrar más detalles en entrada de blog de Google AI .
Traducido del artículo en inglés «Lyra audio codec enables high-quality voice calls at 3 kbps bitrate«

Publicaciones traducidas automáticamente
